Abstract:
•
We introduce a hybrid emotion recognition model that combines a pre-trained EfficientNet backbone with LSTM to capture the temporal dynamics of facial expressions. Unlike traditional static FER approaches, our model processes video sequences to classify valence and arousal into 21-level categories (from -10 to 10), enabling more accurate emotion estimation over time. The system is trained on the AFEW-VA dataset and outperforms baseline CNN-LSTM architectures, demonstrating the benefits of integrating spatio-temporal modeling in affective computing.
◦
Paper:
 Results
Results
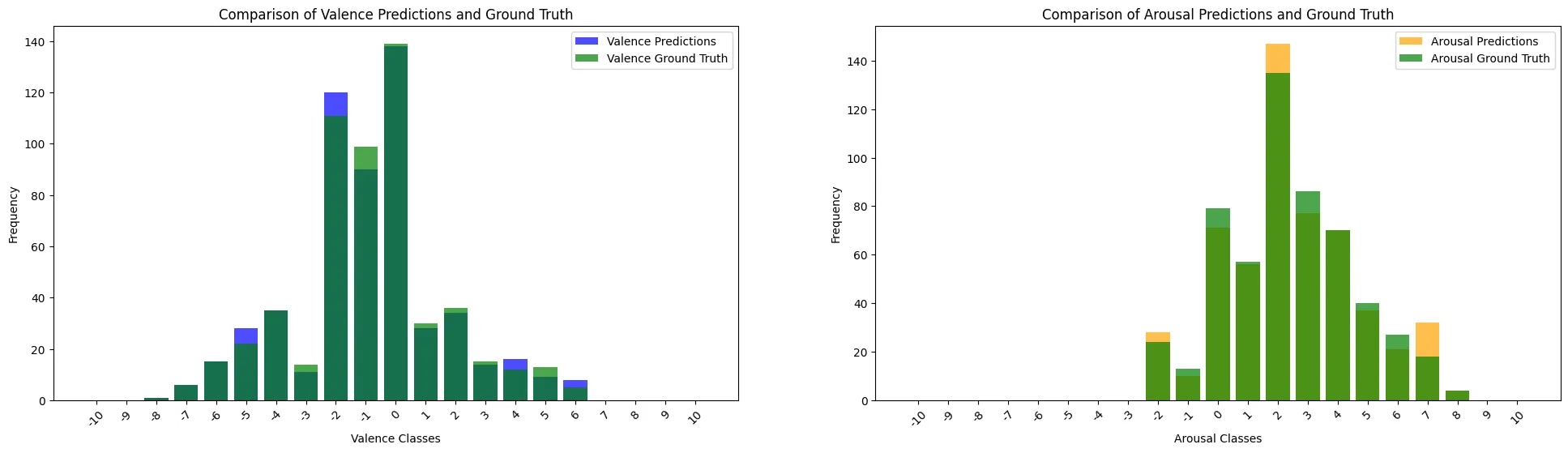
Metric | Valence | Arousal |
F1 Score | 0.8938 | 0.8223 |
Accuracy | 0.9222 | 0.8517 |
CCC | 0.9738 | 0.9613 |
•
Compared to ResNet-50 baseline, our model improved the CCC score by over 60% (Valence: 0.31 → 0.97)•
EfficientNetLSTM achieved superior spatio-temporal representation despite smaller batch sizes and longer training time (7 hrs vs. 6 hrs)